InsectAgent: mobile insect recognition with VLM and on-device vision
A walkthrough of how the InsectAgent app blends a classic vision model with a lightweight multimodal model (FastVLM) to identify insects on your iPhone, and only “thinks harder” when it needs to.
InsectAgent was presented at ISVLSI 2025
This post is designed for readers with little to no coding experience. We’ll keep things visual and plain-language, and focus on the why and how of the app’s hybrid pipeline on iPhone.
I hope you find this exploration both accessible and useful!
Introduction
Field reality: cell coverage can be patchy (or nonexistent) around traps and plots. When your model depends on the network, everything from retries to latency becomes unpredictable. That’s why running locally matters here, beyond privacy alone.
Spotting and identifying insects early can protect crops, reduce chemical sprays, and improve our understanding of seasonal dynamics. The challenge on mobile is achieving good accuracy with reliable, offline behavior.
InsectAgent takes a pragmatic approach:
- Fast local guess: a compact image classifier runs on-device and proposes likely species.
- Think harder only if needed: a lightweight multimodal model (FastVLM
) compares the photo against short species cues to resolve tough look-alikes.
The result feels snappy on easy photos and smarter on ambiguous ones—no cloud round-trips and no dependency on spotty field networks.
What is InsectAgent?
InsectAgent is an iOS app (Swift/Xcode) (code) that demonstrates hybrid insect recognition on modern iPhones:
- A ResNet-18 classifier
provides top-k candidates quickly. - FastVLM
, a small multimodal LLM, is engaged only when the classifier isn’t confident, using brief, visual-first species descriptions (color patterns, wing venation, antenna shape, etc.) to reason about which candidate fits the image best.
Why this design?
- Many photos are “easy wins”, the correct class is confidently top-1.
- For borderline cases, the right class often sits in the top-k; a little text-guided reasoning helps pick the winner.
- Doing this conditionally keeps the common case fast while improving the hard cases.
InsectAgent Pipeline
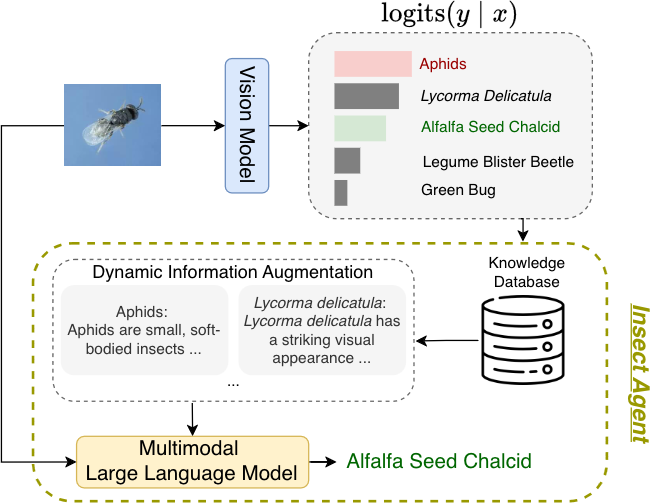
Pipeline components (at a glance)
1) Vision model → top-k logits A compact CNN (say, ResNet-18) produces logits and a ranked list of species candidates. If the top-1 confidence ≥ τ (a configurable threshold), we return that label immediately.
2) Dynamic information augmentation (conditional) If confidence is low, the system fetches short, visual-first cue cards for the top-k species (e.g., “yellow-black banding,” “hind-wing ocelli,” “clubbed antennae”) from a knowledge base.
3) Multimodal reasoning A MLLM compares the input image with those cue cards, weighs evidence, and selects the best match—often correcting near-misses among visually similar species.
Results
On-device variants (FastVLM
100 random insect images from IP102
| Method | Latency (s) | Accuracy (%) |
|---|---|---|
| ResNet-18 | 0.150 | 46.47 |
| ResNet-18 + FastVLM 0.5B | 3.016 | 51.18 |
| ResNet-18 + FastVLM 1.5B | 7.205 | 57.06 |
| ResNet-18 + FastVLM 7B | Out of Memory | Out of Memory |
Notes.
- The threshold τ governs how often the VLM is invoked: higher τ → more VLM calls (better accuracy, higher latency); lower τ → fewer calls (faster, slightly lower accuracy).
- The 0.5B and 1.5B VLMs provide a meaningful accuracy bump over vision-only while remaining feasible on device.
- For broader benchmarks and ablations (e.g., different top-k sizes, cue length), see the paper
.
Video demo
Conclusion & next steps
Pairing a fast vision model with conditional multimodal reasoning gives the best of both worlds on mobile: quick answers when the photo is clear and expert-like judgment when species look alike—without relying on flaky field networks.
What’s next:
- Richer cue cards — concise, visual-first snippets per class (color/venation/antennae/legs).
- More classes & field data — expand coverage and robustness with diverse outdoor images.
- Explainability UI — “why not this species?” side-by-side comparisons to aid learning and trust.
- Lightweight field guides — offline mini-guides for common pests and pollinators.